
Faculty of Engineering > Department of Computer Science >
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SRL Human Attributes Dataset
For the purpose of full-body human attribute recognition in RGB-D, we acquired and annotated a large, gender-balanced RGB-D dataset containing recordings of over 100 persons under controlled conditions. The data has been collected at 15 Hz in three different indoor locations under controlled lighting conditions and annotated with gender and age. Out of 118 persons, 105 (58 female, 47 male) agreed for their recorded data to be shared with other research institutions. The mean age of the subjects is 27 years (σ = 8.7), the age of the youngest participant is 4 and the oldest 66 years. 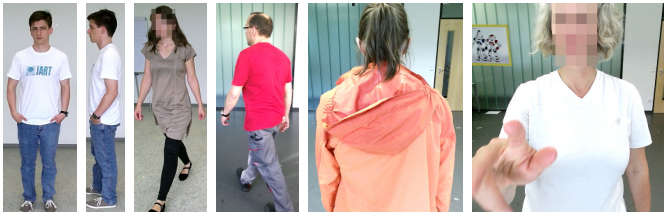
The sensors used for the recording are the ASUS Xtion Pro Live (internally similar to Kinect v1) and the Kinect v2, so as to make it possible for researchers to study effects of different RGB-D data qualities, with the Kinect v2 offering an around 4x higher resolution in depth. For the latter, an initial 75% of the data were recorded using a developer preview version of the sensor, where we did not observe any notable difference in data quality compared to the final version, apart from the range limitation to 4.5m. The two sensors were stacked on top of each other and recorded all sequences at the same time. We did not notice any cross-talk effects between the sensors which is likely due to the different measurement principles, structured light for Kinect v1, time-of-flight for Kinect v2. They were mounted at around 1.5m height and tilted slightly downwards, approximately replicating the setup of a typical mobile robot or handheld device. In total and without subsampling, the dataset contains over 100,000 RGB-D frames. For each of the two sensors, this corresponds to 100 GB of extracted RGB + depth image regions of interest, foreground segmentation masks, colorized depth images and point cloud normals, or alternatively to about 40 GB of pre-extracted RGB-D point clouds in PCD format.
In each recording, the subject performs 4 different standing and walking patterns that have been designed to cover all relative orientations and an RGB-D sensor range of 0.5m to 4.5m: 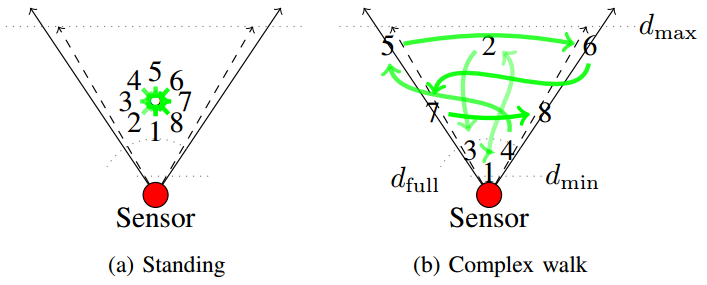
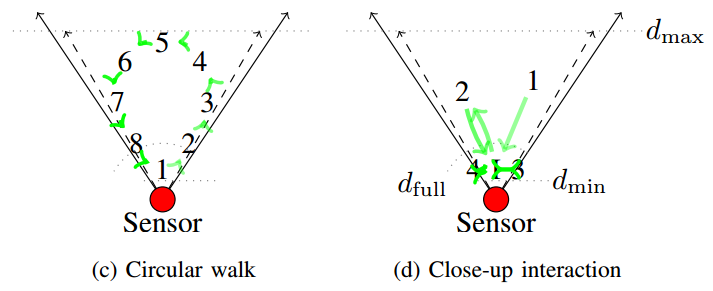
In sequence 1, the subject is standing at around 2.5m distance from the sensor and rotates clockwise in 45° steps (no continuous data capture, 1 image per step). Sequence 2 (typical length ~370 frames) consists of a video of the person performing a complex walking pattern, so as to capture various distances from the sensor and relative orientations. In sequence 3 (~300 frames), the person walks on a circle that covers almost the entire view frustum, in both clockwise and anti-clockwise direction. Finally, sequence 4 (~280 frames) simulates a close-up interaction with a robot, where the subject steps back, forth and sideways in front of the sensor as if he/she is physically interacting with the robot's touch screen or manipulator. The sequence is thought to be a relevant benchmark for human-robot interaction that contains many vertical and horizontal occlusions of people as well as cases of missing out-of-range depth data. Below figures visualize the patterns in sequences 1 – 4.
The recordings cover three mostly empty indoor locations, allowing easy foreground/background segmentation, that are shown in the following pictures. Most subjects have been recorded only once in one of these locations. 
We further post-processed the data as shown in the figure below. To obtain foreground segmentation masks, for each frame, we first remove all points inside of and within a certain noise margin of the ground plane. Then, we apply a depth-based ROI extraction method that projects a height map onto the ground plane and finds a local maximum. We then center a cylinder at the maximum and mark all points inside the cylinder and above ground as foreground. This yields binary foreground/background segmentation masks as shown in the figure below. Additionally, we provide point cloud normals for the extracted ROI that have been computed using a k-NN method with k=25. 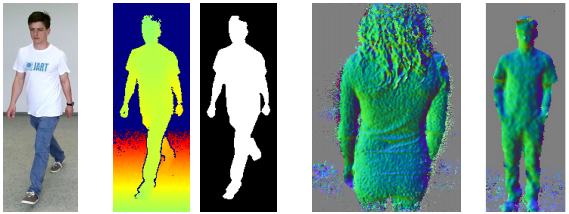
As a result of this post-processing, our dataset's format is largely compatible with the University of Washington's (UW) RGB-D object dataset. The frames of each person instance are stored in a separate folder (person_XXX). In the image-based version of the dataset, each person folder contains the following files: 

These files have the following meanings:
In the point cloud-based version of the dataset, each person folder instead contains the following files: 
with the following meanings:
The general file naming scheme is A few persons were recorded multiple times in different locations and/or appearances (e.g. with jacket and without, with backpack and without). This explains why there are 137 recordings of 118 people. A re-recording of a previously encountered person is indicated by a person instance number XXX > 700. E.g. 709 is the first re-recording of person 009, 809 is the second re-recording of person 809, and so on. Persons with a three-digit number XXX > 100 have not been recorded multiple times. The annotations for the entire dataset are provided in a distinct, space-separated text file containing the person identifier, age in years, and gender (male / female).
The SRL Human Attribute Dataset is available to other researchers upon request. We ask you to fill out a form, indicating the intended usage, your name and affiliation, as well as signing an agreement to not share the data with third parties and to properly anonymize the faces visible in any image that you include in a publication. Once you sent us a scan of the signed form via e-mail, we will reply to you with a download link where you can download:
The ASUS Xtion Pro Live/Kinect v1 version is currently not available for download (due to a quantization error in depth encoding, we need to re-generate the data for this sensor from raw files). Click here for the Dataset Release Agreement Form
If you use this dataset for your research, please cite our papers:
Real-Time Full-Body Human Gender Recognition in (RGB)-D Data
Linder, T., Wehner, S., Arras K.O.,
IEEE International Conference on Robotics and Automation (ICRA'15), Seattle, USA, 2015.
Real-time full-body human attribute classification in RGB-D using a tessellation boosting approach
Linder, T., Arras K.O.,
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS'15), Hamburg, Germany, 2015. |
||||||||||||||